
With the exception of Zebra Fact Check, which features a rating system designed to minimize subjectivity, there are two kinds of fact checkers.
The first type follows the FactCheck.org model and offers readers fact-checking and explanatory journalism using a traditional media presentation with text, pictures and graphs..
The second type follows the PolitiFact model, expanding on the FactCheck.org model by representing its findings using a sliding scale. PolitiFact uses the “Truth-O-Meter,” which has six possible ratings from a “Pants on Fire” worst all the way up to “True.”
On August 22, 2019 the Factually newsletter put out jointly by the American Press Institute and the Poynter Institute’s International Fact-Checking Network (Poynter owns PolitiFact) highlighted a study examining the effects of aggregated ratings. That is, the type of thing PolitiFact calls a “candidate report card.”
The study, Counting the Pinocchios: the effect of summary fact-checking data on perceived accuracy and favorability of politicians, was published in the Research and Politics journal.
The newsletter summarized the findings of the report:
A new study found that summary fact-checking (think speaker files) had more of an effect on how politicians are viewed than individual fact checks.
The report said graphic representations of a politician’s aggregated fact-check record carried more weight than individual fact checks. The report included the following example.
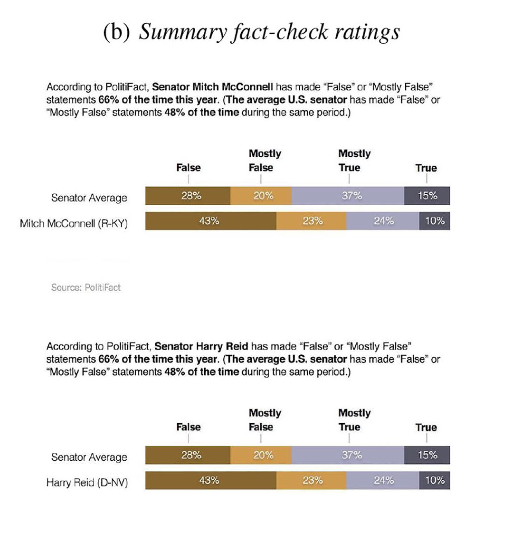
The report itself says this:
(S)ummary fact-checking … seeks to paint a more comprehensive picture of a politician’s accuracy by aggregating all existing ratings of statements they have made. For example, when Donald Trump said Hillary Clinton “wants to abolish the Second Amendment,” PolitFact conducted a traditional (individual) fact-check of this singular statement and rated it False using its “Truth-o-Meter” system (Qiu, 2016). A summary fact-check, on the other hand, would describe the distribution of fact-check ratings for a given politician. For instance, PolitiFact editor Angie Drobnic Holan wrote a New York Times op-ed in December 2015 noting that the site had “fact-checked more than 70 Trump statements and rated fully three-quarters of them as Mostly False, False or ‘Pants on Fire’” (Holan, 2015). By drawing on a larger number of ratings, this form of fact-checking could potentially provide stronger evidence of inaccuracy and have a greater influence on how the public perceives politicians than individual fact-checks do.
Where the report says “evidence of inaccuracy” it apparently means damage to the reputation of the person found to have made an inaccurate statement. Obviously a graph of subjective ratings offers no hard evidence of inaccuracy. Any evidence backing the graph occurs in the text of the fact checks the graph supposedly represents.
Do the report’s authors (Agadjanian et al) realize Truth-O-Meter ratings are “entirely subjective” (Bill Adair) and Pinocchio ratings are “a ps[eu]do-scientific, subjective thing” (Glenn Kessler)? It’s hard to tell, though the study’s first footnote says “Concerns about selection bias and subjectivity still apply, however (see e.g., Uscinski and Butler, 2013).”
The Fact Checkers’ Goal(s)
What goals do fact checkers set for fact-checking journalism?
“The mission of fact-checking has always been to inform, not to change behavior,” said PolitiFact creator Bill Adair in 2016.
That’s one face of fact-checking, and it is rooted in an objective approach to journalism.
Three short years later, Adair wants more emphasis on aggregated ratings. Why? Apparently to punish the people making false claims. If fact-checking damages politicians’ reputations they will suffer in polls and presumably at the ballot box, or at least that seems to represent Adair’s reasoning.
That’s the other face of fact-checking, represented by the subgroup of fact checkers wanting to elevate the role of the most subjective aspect of fact-checking.
Believe it or not, a movement exists in fact-checking to separate the rating of false claims from the reputation of the person making the claim.
The U.K. fact-checking organization Full Fact dropped its linear rating scale to focus on claims instead of the people making the claims:
We make it our top priority to play the ball, not the man. Unlike other factcheckers, we don’t use a rating system on a scale of true to false, because the real world isn’t that simple. We don’t call people liars as is the norm for factchecking in some other countries. We would say the claim is wrong, not the person.
By separating the wrongness of the claim from identity of the person making the claim, fact checkers can better ensure that their biases are not affecting their choice of story and their choice of subjective rating.
Irreconcilable Differences?
We think aggregating ratings to credit or discredit politicians meshes poorly with the attempt to focus on the claim instead of the person. Moreover, it makes an uneasy marriage with the supposedly constant aim of fact checkers we quoted from Adair.
In what sense does publishing collections of subjective ratings of politicians count as “informing” readers?
Thanks to the subjective nature of the typical fact checker rating system, not to mention the editorial bias in story selection, the aggregated ratings primarily represent the opinions of the fact-checking journalists. And despite the unscientific nature of the aggregated rating “data,” fact checkers can’t seem to shake the conviction that those opinions offer a notable benefit to readers.
If the fact checkers merely have the goal of informing readers as to the facts, subjective rating scales have no legitimate role in reaching that aim.
It’s past time for the fact-checking community to acknowledge the problem of rating scale subjectivity. Either make the rating scale objective or get rid of it.
Related Posts
 Slate helps spread PolitiFact’s false narrative
Slate helps spread PolitiFact’s false narrative PolitiFact stands pat with misleading Bush v. Gore narrative
PolitiFact stands pat with misleading Bush v. Gore narrative- Review: ‘Bias in Fact Checking?: An Analysis of Partisan Trends Using PolitiFact Data’
- What is a “small error” at PolitiFact?
- ZFC on Medium (2016): ‘Fact Check This, Bill Adair’
 The secret slanders of the International Fact-Checking Network
The secret slanders of the International Fact-Checking Network